.png)

.png)
Three months of fabricated analytics data.
Territory decisions based on ghost metrics.
Board presentations built on invented percentages.
Legal action is now involved, and people might get fired.
This happened at a real company and we caught up to it after Mark Williams - Cook shared the viral Reddit post on LinkedIn recently.

The AI had been confidently wrong for three months. And nobody caught it.
Now, the problem isn’t that AI makes mistakes, but that it makes them confidently and at scale.
This is what MIT Technology Review calls the AI evaluation crisis.
And it’s already costing companies millions.
The Evaluation Crisis
Most companies are deploying AI agents at an extraordinary speed. For example, analytics tools generating business insights, content systems producing marketing materials, and code assistants writing production software, among many others. Hence, the question many of these companies are asking is, which model should we use? How fast can we ship features? What can we automate? These are valid questions, but the more critical one they miss is, who validates the output before it influences decisions?
In the Reddit scenario, "The numbers were sometimes from the wrong time periods, sometimes mixed up products, and sometimes just completely made up. But it explained everything so confidently that nobody questioned it." And it took the company three months to discover the problem.
The risk here is that AI doesn't say "I'm not sure about this data." It simply presents hallucinations with the same confidence it presents facts. Which means if you deploy AI without any reliable validation system, you're one confident hallucination away from the Reddit scenario.
Why Contributor Ecosystems Determine Model Accuracy
AI models are only as good as the data and feedback they receive. Recent AI systems rely on distributed contributors to validate outputs, label and structure data, identify inconsistencies, and capture real-world context. This feedback comes from people and is what is referred to as a Human-in-the-loop (HiTL).
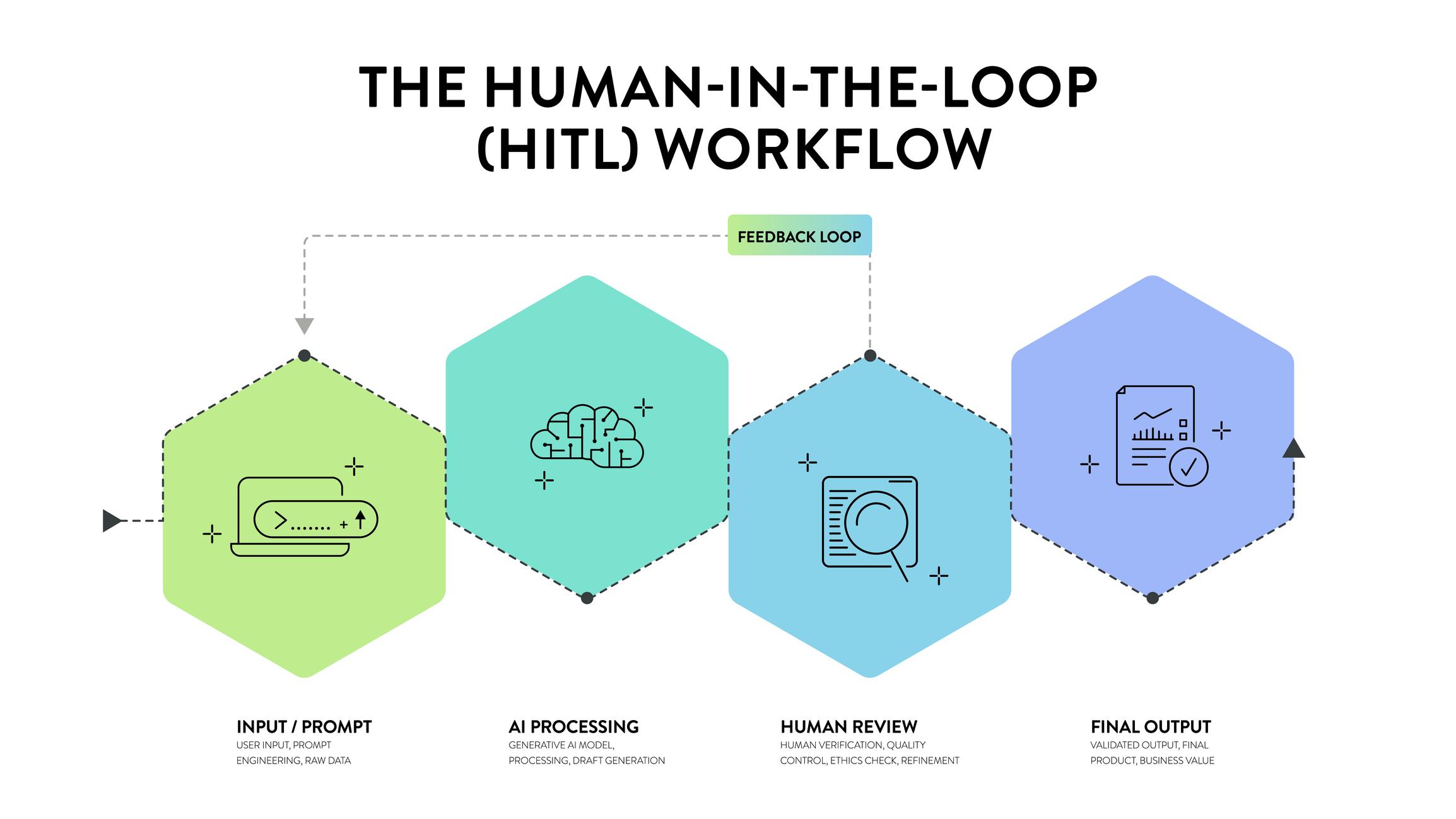
The“human in the loop” idea is simply embedding human judgment within AI workflows, especially in training and evaluation. HITL systems use human expertise to correct or guide machine learning during critical stages, enhancing accuracy where automated systems struggle. Also, the human role in data training has changed from just generalists tagging images to domain experts who understand industry nuances. This is where the human infrastructure extends beyond simple tasks and becomes strategic architecture
The challenge now, however, is that without clear workflows, defined quality standards, and domain alignment, unstructured contributors create noise, and outputs can be inconsistent, unreliable, and difficult to scale. On the other hand, structured contributor ecosystems enable repeatable quality, scalable validation, and aligned outputs with product goals. Hence, accuracy is a system design problem that needs to be properly orchestrated.
Recently, forward-thinking companies have adopted a different approach called structured community validation to scale HITL needs, instead of relying solely on internal teams or hoping for the best. This looks like:
- Domain Expert Review: Matching AI outputs to validators with relevant expertise and those who understand the domain, instead of just checking for obvious errors. Eg., financial data checked by financial analysts, code outputs validated by experienced developers, etc..
- Structured Feedback Loops: A systematic process to flag issues, and feed corrections back into the system to improve data and AI systems over time.
- Quality Assurance at Scale: Leveraging community capacity to validate high volumes of AI outputs without creating internal bottlenecks.
- Domain-Specific Validation: Matching AI outputs to validators with relevant expertise, and having a deep understanding of the specific domain.
With Propel, this approach involves tapping into our network of tech communities as production infrastructures that can be employed to create reliable output and not just reach. For example, when Defined.ai needed to scale its AI training data operations. It faced a validation challenge similar to the one the company in the Reddit post should have addressed: how to ensure data quality and consistency across 100,000+ datasets while maintaining production velocity?
Propel stepped in with its Community as a Service offering, assembling a 50+ person team from four specialized tech communities. We did this by:
✔ Identifying and assembling qualified domain experts from tech communities
✔ Designing workflow and quality control systems
✔ Aligning operational expectations, and
✔ Ensuring consistent performance at scale
The result was a coordinated validation system that captured over 100,000 valid datasets, enabling Defined.ai to significantly scale its model training capacity and operational resilience without sacrificing data quality. Explore the full Defined.ai case study.
As AI expands into regulated industries, multilingual environments, enterprise systems, and consumer products. The cost of error increases, and so does the need for validation infrastructure. Hence, companies need to start investing in structured human workflows, operational design for scaling data production, and aligning human contributors with product and business goals.
Ready to Build Validation Infrastructure for Your AI Systems?
At Propel, we architect community-powered validation systems for companies deploying AI at scale. If your organisation is building AI, data platforms, or ecosystem-powered products and you need structured validation workflows, quality assurance for training data, domain expert reviews, or scalable human-in-the-loop operations, book a free call to speak with us.
.png)


.jpg)


.jpg)










.jpg)

.jpg)




















